

Create Once, Publish Everywhere
At NewCity, we lean heavily on the COPE content strategy to build custom websites. COPE lets you publish a chunk of content in multiple places across the site without having to manually add the same thing each time or needing to update each place when there’s a change. This can be handy for simple deadline warnings and sign-up links as well as more complex design pieces like a detailed contact info block or big event promo.
More flexibility, more power
Using the COPE strategy, we build flexible content types CMS authors use to create complex web pages. They work like a set of Lego blocks, with discrete chunks of content you can select, type into, and move around the page to build a fancy custom graphic layout.
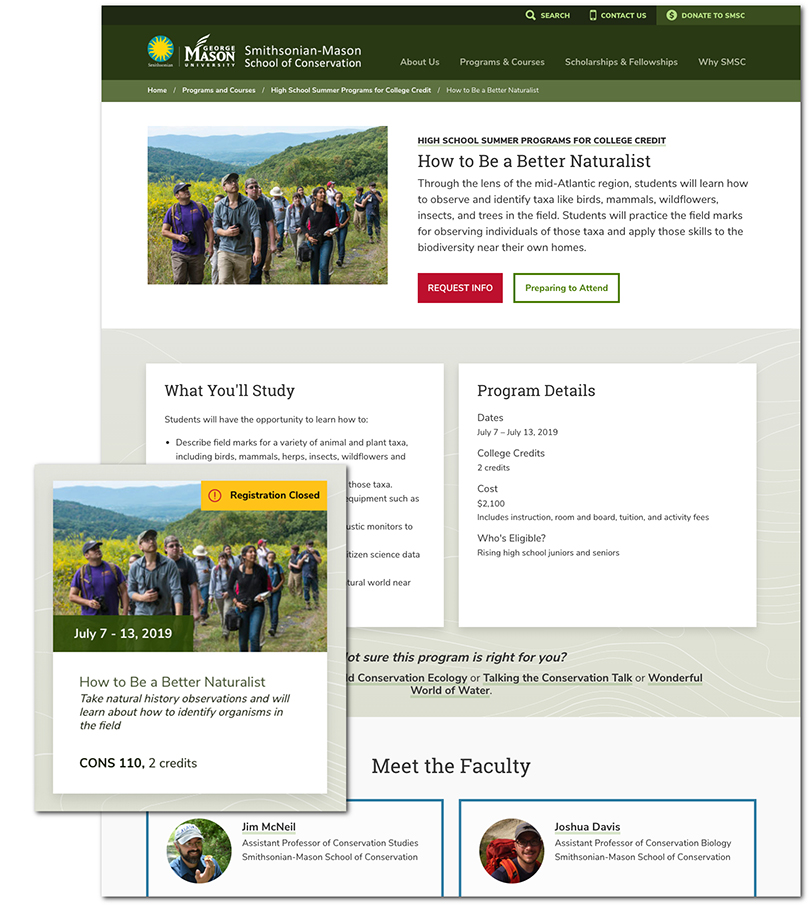 This teaser card for a “How to Be a Better Naturalist” course never had to be “touched” by human hands, it appears automatically on the page that lists all courses. It takes the information stored on that course’s node (page), reassembles the essentials (title, credits, image, etc.) in the card format, and sends it to the Course List page, complete with an automated warning marker once the assigned registration deadline passes.
This teaser card for a “How to Be a Better Naturalist” course never had to be “touched” by human hands, it appears automatically on the page that lists all courses. It takes the information stored on that course’s node (page), reassembles the essentials (title, credits, image, etc.) in the card format, and sends it to the Course List page, complete with an automated warning marker once the assigned registration deadline passes.
It puts powerful tools at a CMS author’s fingertips that give you more control over your content’s presentation and organization — no coding required.
It also means we can give authors access to drop-dead simple data integrations like news and event feeds, and reusable chunks of content, like an auto-populated preview of a bio profile complete with headshot image that you can drop onto pages where an employee’s name is mentioned.
Entities in Drupal
Though we build these flexible content types into both Drupal and WordPress, Drupal is especially convenient for creating those content relationships that are central to a COPE strategy. It stores content in “entities,” which is an overly existential word for anything that can have fields attached to it. Entities are the fundamental Drupal data structure, and they make it easy to set up data queries that extract elements from one chunk of content and inject them into another.
Drupal has a particular vocabulary to define the hierarchy of its entity structure, and knowing the terms can help explain how some of these items work together on the back end to form a website on the front end. Let’s start again at the top with entities.
Entities have “entity types” to describe what kind of entity you’re working with and what it’s used for. Some examples of entity types are:
- Node – a page or other individual content record, like a calendar event, bio profile, news article, etc.
- Taxonomy_term – a tag, used to collect and drive content by category or purpose
- Paragraph – a reusable grouping of fields you can use to build page layouts, like an image gallery, a callout box, or a block of text
- User – a person’s account for accessing the CMS
A developer must define each entity type (namely, determining what fields should go in it) and assign behaviors and rules for it to follow using an API.
Bundles and content records
Another layer down, Drupal uses “bundles” as classes to further define the broad category of an entity type. Bundles are used to create and structure the content — the stuff that users will see on the front end. Examples of bundles include:
- Content type – a template, or group of defined fields and settings that can be used to produce a series of similarly structured content nodes (basic page, blog post, etc.)
- Taxonomy vocabulary – a set of terms in a taxonomy that can organize content or drive a specific function, like department, news topic,
- Custom block types – Containers of persistent content that go into a particular region of (usually multiple) pages, e.g., a set of social media icons to display in the sidebar or footer
To give an analogy: an entity type is like a broad category of animal (“mammal” or “reptile”). A bundle would be a specific species, like “dogs” or “cats.” And each content record is like an object: a specific instance of a class (“bundle”) that extends an abstract class (“entity type”). The content records are individual dogs and cats, “that dog Rex” and “that cat Snowball.”
Building pages with content types
Content types are what authors come in contact with the most in the CMS. These are what you select once you’ve decided what type of page you want to make, and then you fill in the fields to create your web page and change settings that pull in those dynamic chunks of reusable content from other entities scattered across the site.
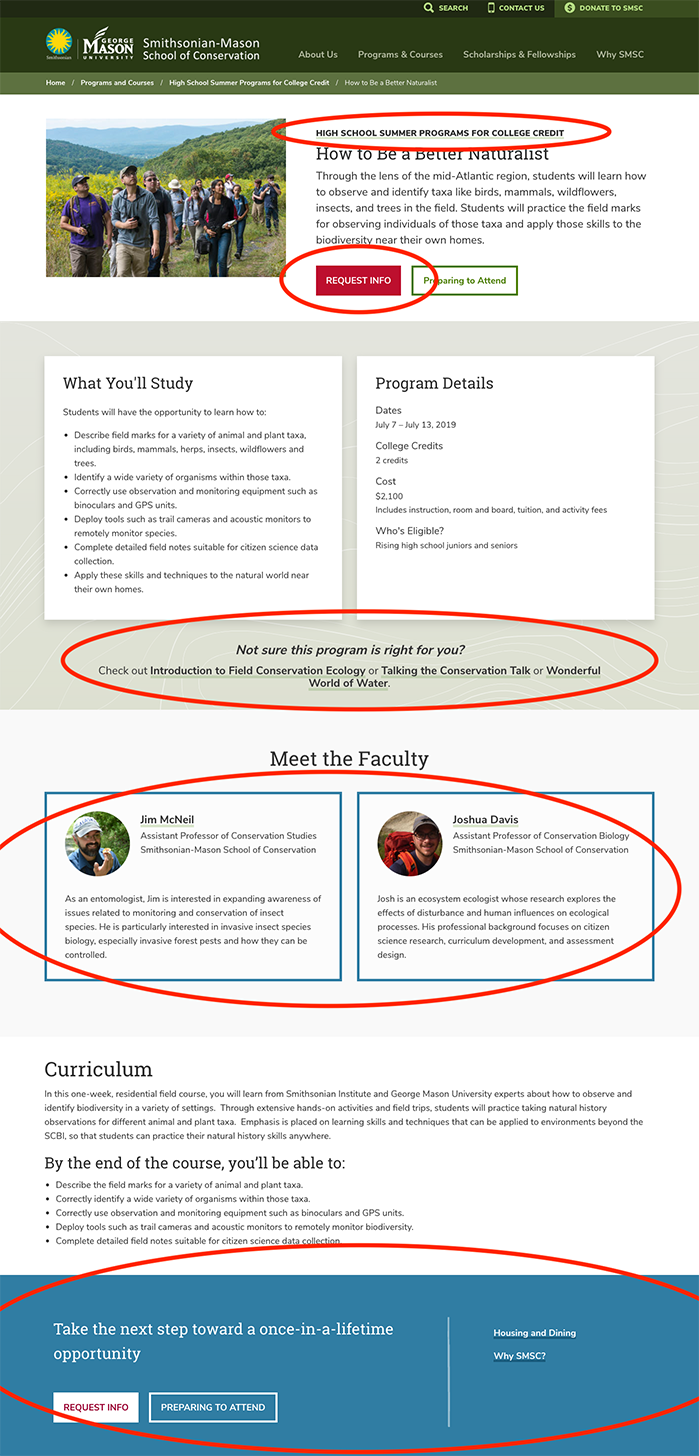 This course page itself is actually full of dynamic pieces that are automatically populated by referencing other content around the site. The faculty blocks, call-to-action panel at the bottom, links to other related courses, and even the super-heading “High School Summer Programs for College Credit” and URL behind the red Request Info button are all automatically-appearing content controlled by selecting associated items in a checkbox or lookahead field, rather than typing text and URLs onto this actual page. When the source content of one of those pieces changes or is unpublished, it will instantly update on this page as well.
This course page itself is actually full of dynamic pieces that are automatically populated by referencing other content around the site. The faculty blocks, call-to-action panel at the bottom, links to other related courses, and even the super-heading “High School Summer Programs for College Credit” and URL behind the red Request Info button are all automatically-appearing content controlled by selecting associated items in a checkbox or lookahead field, rather than typing text and URLs onto this actual page. When the source content of one of those pieces changes or is unpublished, it will instantly update on this page as well.
Common structured content types that contain dynamic content chunks include:
- News
- Events
- Staff profiles
- Product pages (like degrees, for a university site)
- Departments
- Articles in a specific category (like disease types or treatment options, for a healthcare organization)
With great power comes great responsibility
In many CMS setups, creating dynamic feeds and other relationship-driven content is often restricted to developers or admins. By taking advantage of Drupal’s entity architecture, we can give a humble CMS author the freedom to choose when and how to apply those complex items to pages as needed.
But it also means content authors who were once used to just a WYSIWYG interface — an empty box that belonged to and created content for a single sovereign page in the CMS — must now manage a much more complex series of editorial choices. These choices manifest as drop-downs, checkboxes, taxonomy terms, and other sometimes-alienating interfaces that may or may not drive hidden functionality in other places on the site.
Now pages are assembled from smaller groups of content (usually row by row in priority order), some of it made up of references called in from other pages that they won’t be able to see when they’re editing on the back end.
The “page” edit form the author sees isn’t a one-to-one representation of the front end like it used to be — what you’re really doing is writing data into fields that make up an entity, and that data is then saved and stored entity-by-entity in the database (not page-by-page). The fields are just control switches and windows into data that’s floating around in the ether, collected together on this edit form for the convenience of the author, to simulate how the pieces will be recombined and displayed on the front end.
Growing our people along with the system
This new style of CMS gives non-developers more power and flexibility to optimize the layout, graphics, and functionality to suit their specific content. But it also requires a different set of skills — a good eye for layout and design, the ability to rewrite copy to fit, and an understanding of the back end architecture of the site as a whole, so you can control the content relationships and their associated functionalities.
Our content authors can no longer be just anyone with a login who can copy-and-paste — they’ve crossed into the realm of interaction designers. And when we switch to this new style of CMS, we have to make sure we give them the training and resources they need to evolve along with it.